
AI是如何重塑产品经理工作流的?
一、旧世界的困局:产品经理为何总是”忙而无功”
从”文档工匠”到”信息炼金术士”的范式跃迁
产品经理这个岗位,本质上是一场关于信息转化的炼金术——将混沌的市场信号提炼为清晰的产品决策,将抽象的用户诉求转化为具体的系统功能。然而在过去十年里,这场炼金术逐渐异化为一场文档编制工程。
产品经理的一天往往这样展开:打开Axure画几个原型页面,切换到Visio调整流程图,再打开Word文档逐字逐句打磨PRD,最后用Excel表格管理维护需求矩阵。一个按钮的功能调整,需要在四五个工具间来回跳转;一个业务规则的变更,要凭人脑记忆去追溯所有关联文档,耗时数小时仍担心遗漏。PRD从沟通媒介异化为部门间博弈的筹码——写得越厚,显得越专业;评审会上念完几十页,开发真正消化的不足十页。
更深层的困境在于信息损耗的不可逆性。传统工作流像一条漫长的手工流水线:调研所得经过人脑压缩写入PRD,PRD经过开发的理解转化为技术方案,技术方案再经过编码变为系统功能。每一道转手都在丢失上下文,每一次沟通都在引入歧义。产品经理被困在”文档排版师”和”跨部门传声筒”的角色里,真正核心的洞察与判断,反而被挤压在碎片时间的缝隙中。
这不是工具使用不当的问题,而是工作范式的根本性错位——当信息的存储、传递与验证都依赖人肉处理时,效率的天花板早已注定。
二、新范式的诞生:当PRD的读者从”人”变成”AI”
现在很多开发团队让GitHub Copilot、Cursor、Claude Code等AI工具生成80%的代码,开发只需review 20%。当开发都在用AI写代码时,一个尖锐的问题浮现出来:你的PRD还在给谁看?
flowchart LR
subgraph 传统流程["🔄 传统信息链"]
direction LR
PM1["👤 PM"]
PRD1["📝 PRD文档"]
DEV1["👨💻 开发"]
CODE1["💻 代码"]
PM1 -->|"编写"| PRD1
PRD1 -->|"阅读"| DEV1
DEV1 -->|"编写"| CODE1
end
subgraph 新流程["🤖 AI辅助流程"]
direction LR
PM2["👤 PM"]
PRD2["📝 PRD文档"]
DEV2["👨💻 开发"]
AI["🤖 AI"]
CODE2["💻 代码"]
PM2 -->|"编写"| PRD2
PRD2 -->|"阅读"| DEV2
DEV2 -->|"转述需求"| AI
AI -->|"生成"| CODE2
end
style 传统流程 fill:#e8f4f8,stroke:#2c3e50,stroke-width:2px
style 新流程 fill:#fff3e0,stroke:#e65100,stroke-width:2px
style AI fill:#ffe082,stroke:#f57f17,stroke-width:2px
style DEV2 fill:#ffccbc,stroke:#bf360c,stroke-width:2px
当中间多了一层”人脑转述”,信息就开始丢失。开发拿着Axure原型截图给AI,AI不知道这个按钮为何存在、不知道逻辑依赖哪个模块,只能猜测——猜错了,开发再来问,PM再解释,AI再生成,来回折腾。
问题的本质是PRD的读者变了。 以前PRD是写给人类看的,需要详细的背景说明、大段的文字描述、精美的排版格式;现在真正的第一读者是AI,它需要的是结构化的、精确的、可被执行的提示词。这不是工具的升级,而是工作范式的转变。
需要转变的三个核心变革:
第一:存储统一。 PRD、代码、设计稿不再分散在不同平台,而是放在同一个Git仓库中。用Markdown写PRD、用Mermaid画流程图、用代码管理原型,AI能完整理解项目的全部上下文。当AI读取时,它看到的不是孤立的文档,而是相互关联的知识网络。
第二:读者转变。 PRD从”写给开发看”变成”写给AI看,开发来review”。开发不再是需求的第一读者,而是AI理解的验证者。这意味着PRD的写法要从”叙事体”转向”规范体”——减少铺垫,增加约束;减少描述,增加结构。
第三:工作流重构。 PM的时间分配从”40%思考+60%写文档”转向”80%思考+20%验证”。20%时间给AI提供上下文,60%时间让AI生成内容,20%时间验证输出。重点不再是打字速度,而是产品判断力——知道什么是好的,什么是对的。
三、需求挖掘:从”问卷调研”到”AI仿真”
传统用户调研的最大痛点是时间成本与样本偏误。设计问卷需要专业知识,回收周期动辄数周;用户访谈约不到目标人群;定性数据分析主观性强,容易陷入”确认偏误”。
AI重塑这一环节的核心思路是 “合成用户”(Synthetic Users)。在产品早期,利用AI生成特定的用户画像(Persona),进行第一轮”虚拟访谈”。
例如,你可以设定一个”30岁、焦虑、关注理财的职场人”画像,让AI模拟这个用户对你的产品概念进行反馈。它不能完全替代真人,但能以零成本过滤掉80%的逻辑硬伤——那些连AI都觉得不合理的需求,真人大概率也不会买单。
在二手信息处理上,AI实现了全量反馈挖掘。拒绝抽样,将App Store评论、客服对话记录、社群吐槽全部”喂”给AI,进行情感分析和痛点聚类。
工具如Viable可以整合微信、Zendesk等所有客服数据,自动提炼出”用户最急需修复的Bug”和”最想要的功能”报告。
一手信息仍然不可替代,但AI大幅提升了处理效率。调研前生成大纲和问题,调研中录音转文字,调研后快速提取痛点形成报告。关键是,AI能帮助发现反常信号——当AI指出一个与你直觉相反的用户趋势时,你可以要求它追溯来源,验证是真实洞察还是数据幻觉。
Prompt示例:
“你现在是[一线城市35岁职场妈妈],针对这个产品Idea,请用最挑剔的眼光提出3个你绝对不会买单的理由,并深刻解释为什么。”
四、竞品分析:从”人肉截图”到”竞品雷达”
传统竞品分析是体力密集型工作:疯狂截图、录屏、写几十页PPT,汇报完没几天竞品就改版了。产品经理陷入”信息收集”的泥潭,却无暇进行”战略判断”。
AI带来的降维打击在于:将竞品的帮助文档、API文档、甚至财报PDF投喂给AI,直接输出SWOT分析或功能对比表。更进一步,让AI深度对比你和竞品的文案/功能差异,寻找被巨头忽略的”蓝海”缝隙——竞品用户最不满的地方,正是你的机会。
在情报监控层面,工具如Browse.ai、Perplexity.ai可以监控竞品网站变动。一旦竞品更新了定价页面或上线了新功能,自动触发通知并总结变化点。产品经理从”信息猎人”变成”情报指挥官”——设定监控规则,接收结构化报告,专注判断哪些变化值得响应。
关键转变: 竞品分析不再是周期性项目,而是持续性数据流。AI帮你建立了”竞品雷达”,你只需在异常信号出现时做出决策。
五、产品定义:从”写PRD”到”写Prompt”
快捷的演示Demo-VibeCoding(氛围编程)
传统PRD是”产品说明书”,目标是让人类开发理解需求;AI时代的PRD是”执行规范”,目标是让AI直接生成代码。这带来了PRD的后置甚至消失——既然能通过Vibe Coding直接出Demo,代码本身就是最好的文档。PRD退化为”逻辑备忘录”和”边缘情况兜底”。
AI对工作流重塑最深刻的环节是:
想法 → AI生成Mermaid流程图 → 秒悟/Cursor生成UI代码 → 人工微调 → AI反向生成文档归档。
想法是起点,AI是执行者,人是审校者
flowchart LR
subgraph 传统工作流["⏳ 传统工作流:文档驱动"]
direction TB
T1["💡 想法"] --> T2["📝 写PRD/文档"]
T2 --> T3["👨💻 开发编码"]
T3 --> T4["🎨 UI设计+切图"]
T4 --> T5["🧪 测试验收"]
T5 --> T6["📁 补写文档归档"]
end
subgraph AI重塑工作流["⚡ AI重塑工作流:想法驱动"]
direction TB
A1["💡 想法"] -->|"自然语言描述"| A2["🤖 AI生成Mermaid流程图"]
A2 -->|"可视化确认"| A3["⚡ 秒悟/Cursor生成UI代码"]
A3 -->|"AI初稿"| A4["✋ 人工微调"]
A4 -->|"成品"| A5["🤖 AI反向生成文档归档"]
end
T6 -.->|"被取代/重构"| A1
style 传统工作流 fill:#e8eaf6,stroke:#3949ab,stroke-width:2px
style AI重塑工作流 fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px
style A1 fill:#fff9c4,stroke:#f57f17,stroke-width:3px
style A2 fill:#ffe082,stroke:#f57f17,stroke-width:2px
style A3 fill:#ffcc80,stroke:#ef6c00,stroke-width:2px
style A5 fill:#c8e6c9,stroke:#388e3c,stroke-width:2px
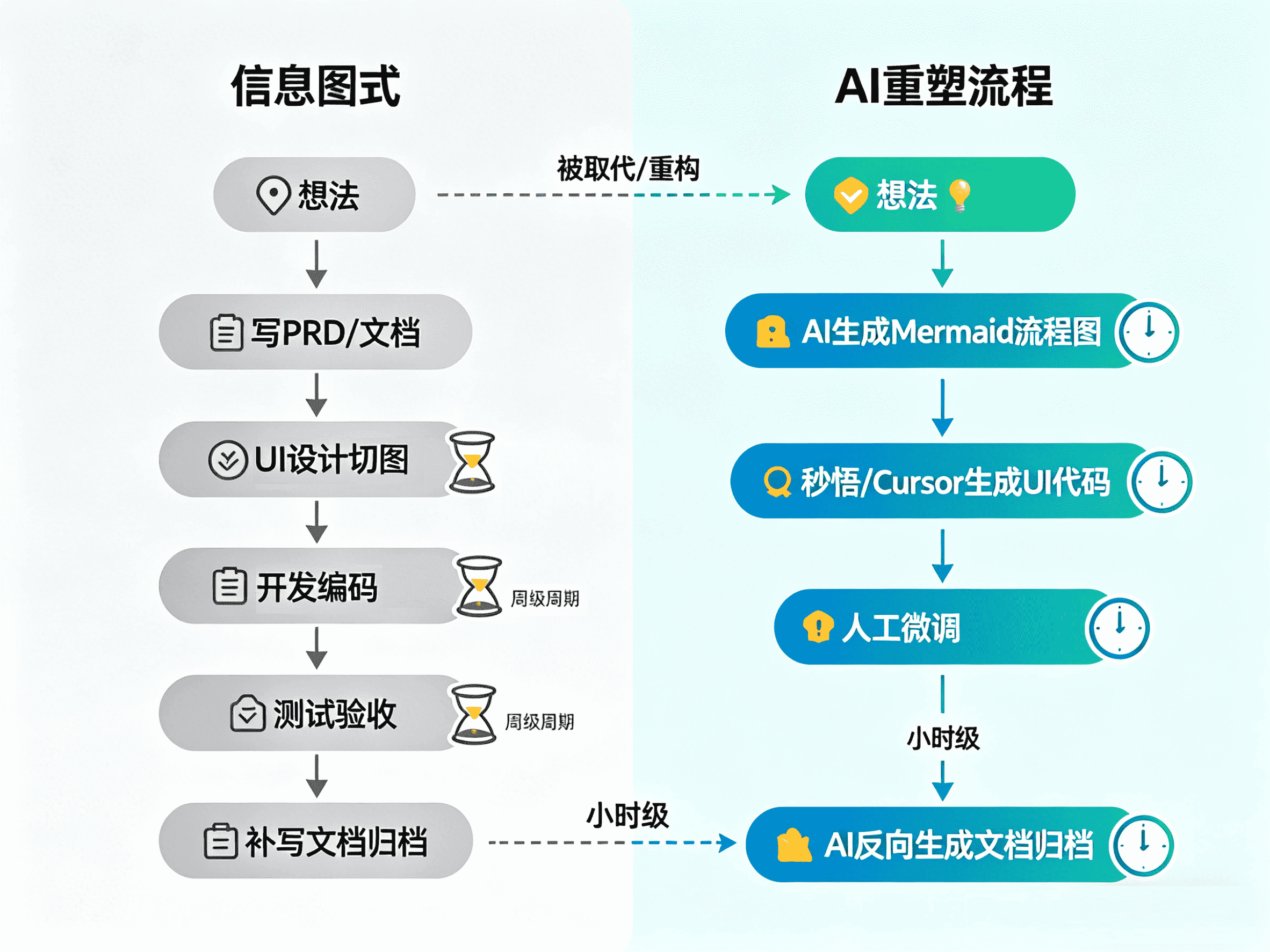
工具层面:秒悟、v0.app和Bolt.new
如登录页描述”一个带有磨砂玻璃效果的登录页,需要暗黑模式”,直接获得可用的React代码和预览。也可以上传手绘草图,AI瞬间理解并生成高保真UI结构甚至代码。
这种”原型驱动”(Prototype-Driven)甚至”代码驱动”(Code-Driven)的工作流,将验证周期从周级压缩到小时级。以前需要几天画的原型,现在两小时就能生成可交互Demo;以前需要反复沟通的视觉效果,现在直接生成代码让开发跑起来看。
更深层的变革是Spec-Driven Development(规范驱动开发)
GitHub推出的spec-kit正在推动这一范式:PRD不再只是”给人看的文档”,而是”给AI执行的规范”,它更适合生产级、可维护的项目。
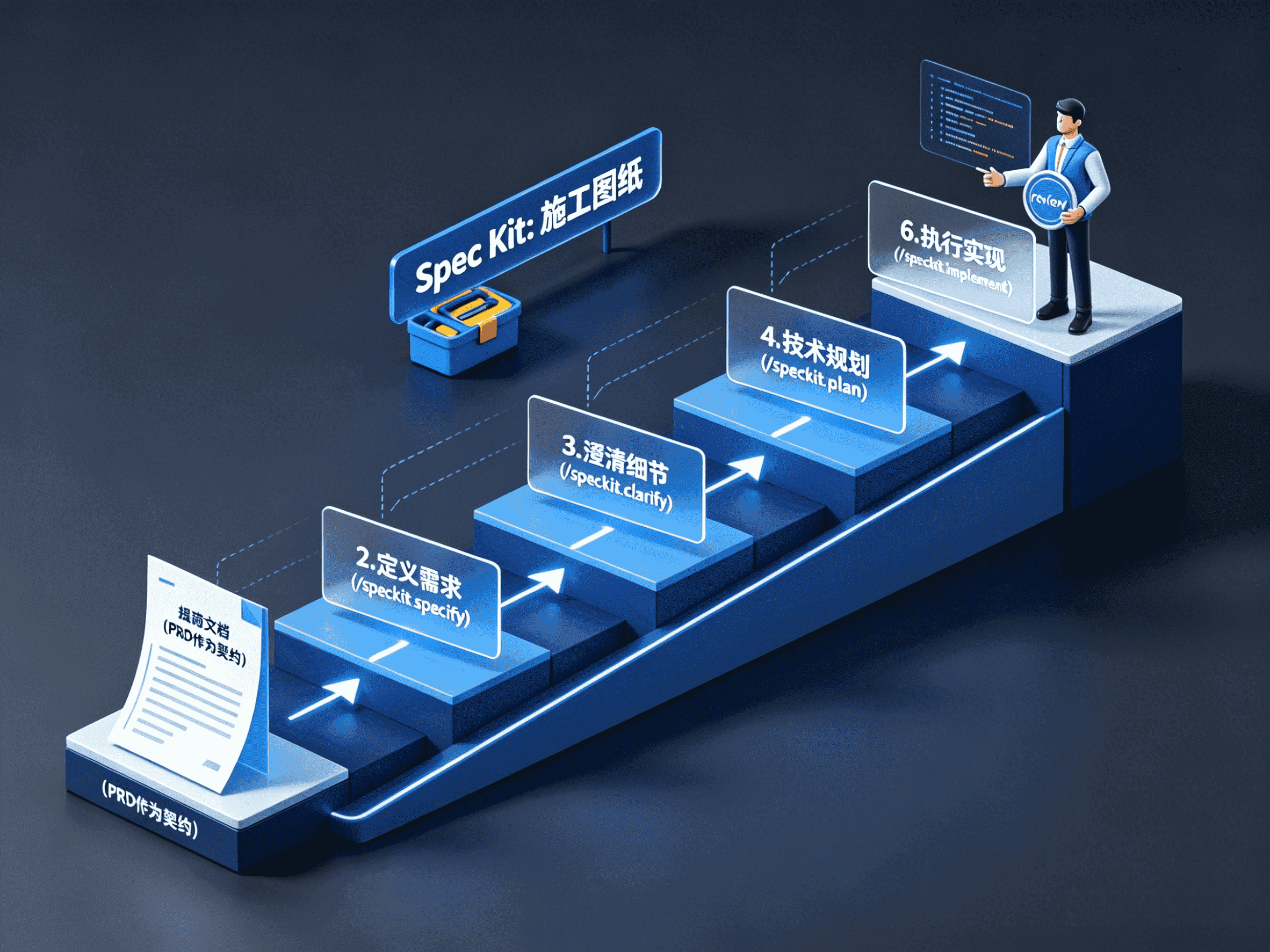
Spec Kit 的理念是:先把”软件该做什么”写成正式的规范文档,再让 AI 基于这份规范去执行,让业务方、产品、开发者和 AI Agent 都从同一份”契约”出发。
Spec Kit 提供了一套标准化的 6 步流水线:
| 步骤 | 命令 | 作用 |
|---|---|---|
| 1. 确立原则 | /speckit.constitution |
创建项目治理原则和开发规范 |
| 2. 定义需求 | /speckit.specify |
描述要构建什么(关注 what 和 why) |
| 3. 澄清细节 | /speckit.clarify |
补充未明确的需求细节 |
| 4. 技术规划 | /speckit.plan |
选择技术栈和架构方案 |
| 5. 任务拆解 | /speckit.tasks |
生成可执行的任务清单 |
| 6. 执行实现 | /speckit.implement |
按规范自动执行所有任务 |
AI直接读PRD生成代码,开发只需检查代码逻辑和PRD理解是否一致。
Spec Kit = 给 AI 编程写”施工图纸”的工具包。它不是替代 AI 编程工具,而是让 AI 编程从”凭感觉”变成”按规范执行”,提升代码质量和可预测性。
SpecKit简单示例
以下是一个基于 GitHub Spec Kit 官方仓库 的 简单示例,展示如何用 Spec-Driven Development 开发一个”照片相册管理应用”。
场景:照片相册管理器1. 项目初始化1
2
3
4
5
# 安装 Spec Kit CLI
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# 初始化项目
specify init photo-album-manager --integration copilot
1 | # 安装 Spec Kit CLI |
这会生成 .specify/ 目录,包含模板和配置。
2. 制定项目原则(Constitution)
在 AI 代理中执行:
1 | /speckit.constitution Create principles focused on code quality, testing standards, user experience consistency, and performance requirements |
生成的 constitution.md 可能包含:
1 | # Project Constitution |
3. 编写需求规范(Specify)1
/speckit.specify Build an application that can help me organize my photos in separate photo albums. Albums are grouped by date and can be re-organized by dragging and dropping on the main page. Albums are never in other nested albums. Within each album, photos are previewed in a tile-like interface.
1 | /speckit.specify Build an application that can help me organize my photos in separate photo albums. Albums are grouped by date and can be re-organized by dragging and dropping on the main page. Albums are never in other nested albums. Within each album, photos are previewed in a tile-like interface. |
生成的 spec.md:
1 | # Feature Specification: Photo Album Manager |
4. 技术规划(Plan)1
/speckit.plan The application uses Vite with minimal number of libraries. Use vanilla HTML, CSS, and JavaScript as much as possible. Images are not uploaded anywhere and metadata is stored in a local SQLite database.
1 | /speckit.plan The application uses Vite with minimal number of libraries. Use vanilla HTML, CSS, and JavaScript as much as possible. Images are not uploaded anywhere and metadata is stored in a local SQLite database. |
生成的 plan.md:
1 | # Implementation Plan |
src/
├── components/ # UI 组件
│ ├── AlbumGroup.js
│ ├── AlbumItem.js
│ ├── PhotoGrid.js
│ └── PhotoTile.js
├── stores/ # 数据层
│ └── AlbumStore.js # IndexedDB 封装
├── utils/ # 工具函数
│ └── dragDrop.js
├── styles/
│ └── main.css
└── main.js
1 |
|
实现策略
Phase 1:搭建 Vite 项目骨架 + IndexedDB 封装
Phase 2:实现相册 CRUD 和日期分组
Phase 3:实现拖拽排序(禁止嵌套)
Phase 4:实现照片上传和平铺预览
Phase 5:PWA 配置和离线支持
5. 任务拆解(Tasks)
Phase 1:搭建 Vite 项目骨架 + IndexedDB 封装
Phase 2:实现相册 CRUD 和日期分组
Phase 3:实现拖拽排序(禁止嵌套)
Phase 4:实现照片上传和平铺预览
Phase 5:PWA 配置和离线支持
/speckit.tasks
生成的 tasks.md:
1 | # Task List |
6. 执行实现(Implement)1
/speckit.implement
1 | /speckit.implement |
AI 代理会按 tasks.md 逐项执行,每完成一项勾选 [X],并生成对应的代码文件。
关键产物总结
| 文件 | 作用 |
|---|---|
constitution.md |
项目治理原则,约束所有开发行为 |
spec.md |
需求规范,回答”做什么”和”为什么” |
plan.md |
技术方案,回答”怎么做” |
tasks.md |
可执行的任务清单 |
src/ |
AI 生成的实际代码 |
graph LR
subgraph "🔷 Spec Kit 规范驱动开发流程"
direction TB
A[用户: 我想做一个照片相册管理应用] --> B["🎯 Step 1: /speckit.constitution
制定项目原则"]
B --> C["📋 Step 2: /speckit.specify
编写需求规范"]
C --> D["🔧 Step 3: /speckit.plan
技术规划"]
D --> E["📌 Step 4: /speckit.tasks
任务拆解"]
E --> F["⚡ Step 5: /speckit.implement
执行实现"]
F --> G["✅ 交付: 可运行的照片相册应用"]
end
subgraph "📄 产物文件"
direction TB
B1["constitution.md
项目治理原则
• 代码质量
• 测试标准
• 性能要求"]
C1["spec.md
需求规范
• 用户故事
• 验收标准
• 非功能需求"]
D1["plan.md
技术方案
• 技术栈选择
• 架构设计
• 数据模型"]
E1["tasks.md
任务清单
• Phase 1-5
• 18个具体任务"]
F1["src/ 源代码
• 组件
• 数据层
• 工具函数"]
B1 --> C1 --> D1 --> E1 --> F1
end
B -.->|生成| B1
C -.->|生成| C1
D -.->|生成| D1
E -.->|生成| E1
F -.->|生成| F1
style A fill:#e1f5fe
style G fill:#c8e6c9
style B fill:#fff3e0
style C fill:#fff3e0
style D fill:#fff3e0
style E fill:#fff3e0
style F fill:#fff3e0
style B1 fill:#f3e5f5
style C1 fill:#f3e5f5
style D1 fill:#f3e5f5
style E1 fill:#f3e5f5
style F1 fill:#f3e5f5
六、研发协作:从”求着开发做”到”带着方案聊”
传统需求评审会常被戏称为”吵架会”:PM听不懂技术术语,开发质疑需求合理性,测试抱怨边界情况没说清。信息在每一层传递都在丢失,一个需求至少要讲三遍。
AI重塑协作的方式是建立”技术翻译官”机制。当开发说”技术实现不了”时,PM可以用AI查询替代方案,不再被轻易”忽悠”,建立平等对话。更进一步,PM可以直接用AI生成技术方案草稿,带着方案去沟通,而不是带着问题去求助。
在项目管理层面,Linear的AI功能可自动把杂乱的会议记录转化为结构化的Issues,甚至自动识别合并重复的Bug报告。利用Zapier/n8n搭建自动化流:微信群里的需求零散讨论 → AI总结提炼 → 自动写入Linear/Jira变为待办事项。
智能审查(Smart Review) Qodo.ai在开发阶段介入,分析代码逻辑漏洞,自动生成测试代码,将Bug扼杀在摇篮里。PM不再是”点点点”的人工测试员,而是测试策略的制定者。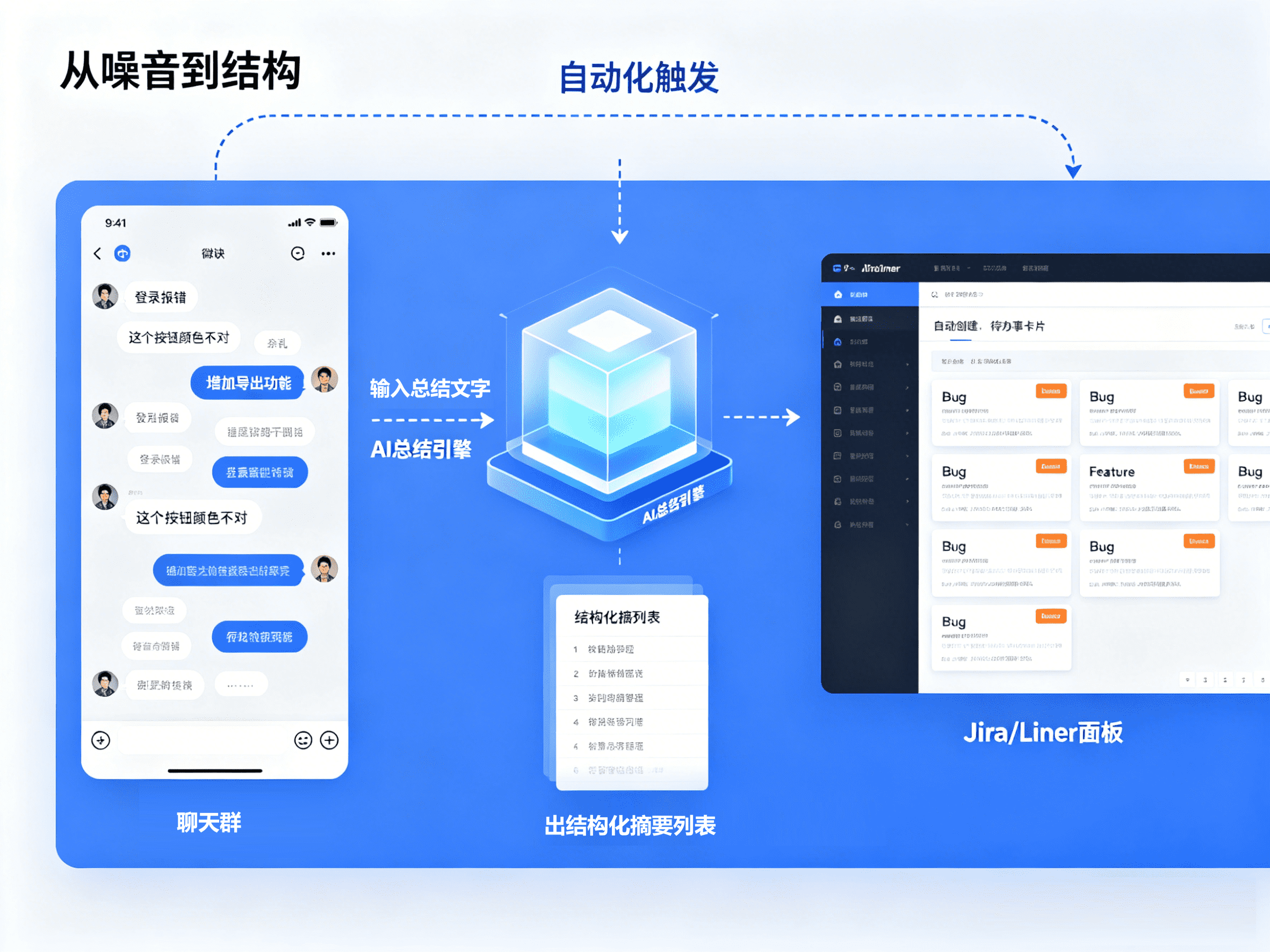
七、需求变更:从”恐惧修改”到”从容迭代”
传统方式下,需求变更是产品经理的噩梦。Axure、Word不像IDE有逻辑关联,修改一个字段需要依靠记忆找出所有相关文档,大项目可能耗时数小时还怕漏掉。
AI时代,这个问题被根本性解决。以Claude Code为例:
- CLAUDE.md文件记录项目背景、架构、核心逻辑,AI一打开项目就理解全局上下文
- 对话历史保存了所有决策过程和 rationale,修改时能自动提醒”之前你说过这个地方不能改,因为XXX”
- grep搜索用正则表达式快速定位任何代码或文档
- MCP记忆功能持久化存储重要决策,即使换新对话也能调取
当你问”我要把用户权限从三级改成五级,会影响哪些地方?”,2分钟后AI列出:PRD的权限设计章节、数据库表结构、后端权限校验中间件、前端路由守卫逻辑、管理后台配置页面——每一处都给出具体位置。
更关键的是流程图也能同步更新。 传统方式下改了逻辑,流程图得手动重画;现在告诉AI”权限改成五级了,帮我更新流程图”,它直接重新生成Mermaid代码,三个分支变成五个,逻辑清清楚楚。PM终于有了类似IDE的能力——不是写文档,而是管理整个项目的逻辑图谱。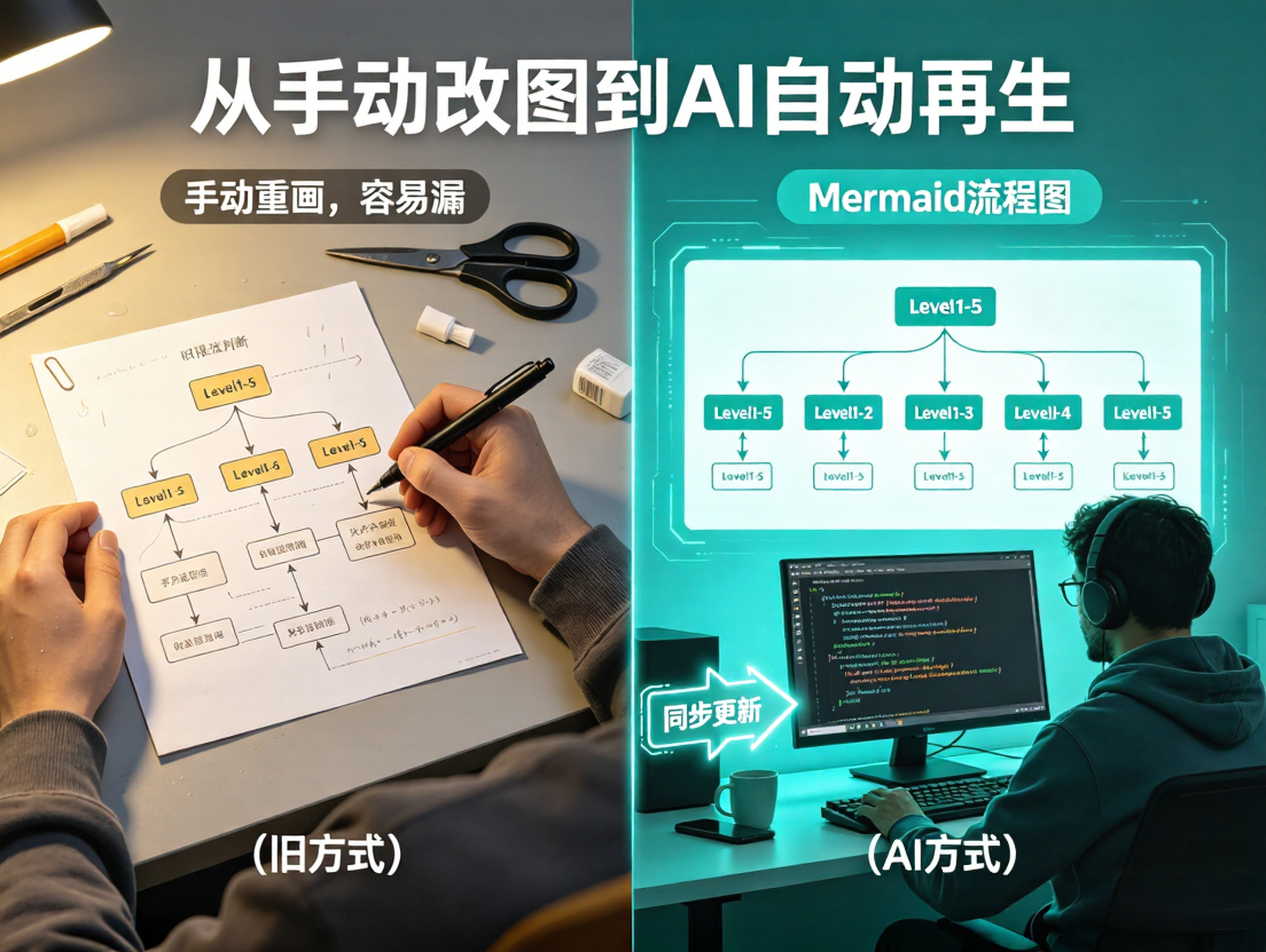
八、运营增长:从”人憋文案”到”AI矩阵方案”
AI让PM直接对GTM(Go-to-Market)结果负责成为可能。
内容工厂模式:利用AI批量生成小红书/Twitter文案、SEO博客、App Store更新日志,建立内容矩阵。Jasper、Copy.ai能深度学习品牌Tone & Manner,保持输出一致性。一条指令可以生成10条针对不同人群(大学生/白领/宝妈)的种草文案,并配套生成Midjourney提示词。
数据探针模式:直接把SQL表结构给AI,让它帮你写查询语句;或者丢入CSV,让它直接画出留存率分析图。Julius AI等工具让”对话式数据分析”成为现实——“帮我分析上个月流失用户的共同特征”,直接出图表和结论。
这意味着PM不再需要依赖数据分析师的基础查询工作,可以自主验证假设、快速迭代策略。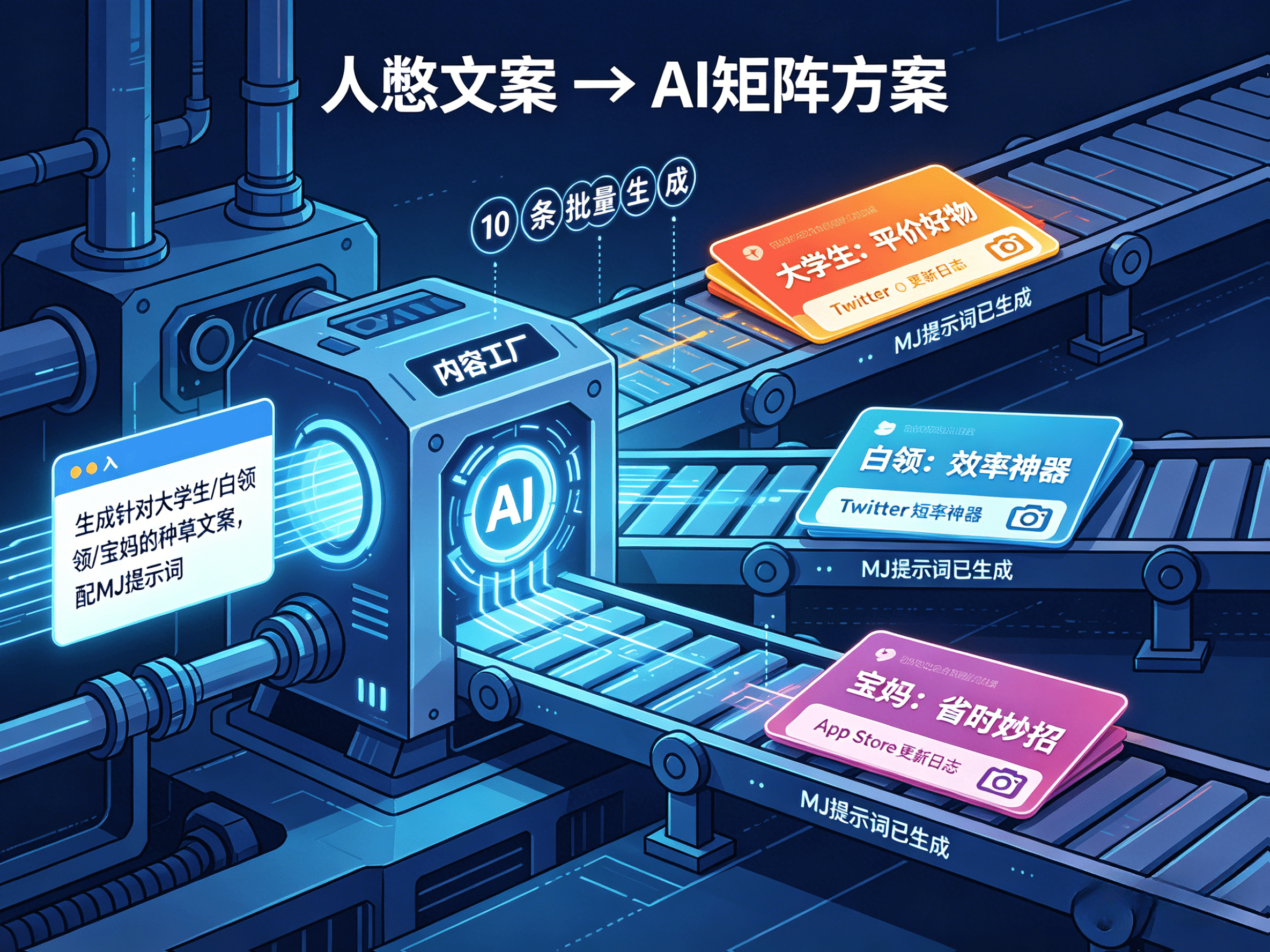
九、组织层面的重构:从”人走信息断”到”AI当项目历史库”
AI对工作流的重塑不仅发生在个体层面,更在组织结构层面引发连锁反应。
项目交接从2-3周压缩到30分钟。以前同事离职,原PM讲3天,新PM看文档5天,还是一头雾水——因为很多信息在脑子里,从未文档化。现在新PM打开AI工具问”帮我理解这个项目”,30分钟掌握70%,剩下的30%随时问AI即可。人走了,信息还在,AI成了项目的”记忆库”。
评审机制从”真人PK”变成”AI预演”。创建多Agent评审团,分别由开发、运营、测试、合规等子Agent组成,每个Agent有自己的人设和目标,由主Agent牵头召开虚拟评审会。甚至可以把”乔布斯分身”请进评审现场,在真实评审前暴露80%的问题。PM从”解题者”变成”出题者”和”最终拍板者”。
知识管理从”文档堆积”变成”活的知识库”。本地项目文件夹作为知识库,整理好上下文让AI读取和操作。越用越顺手,不用每次都解释背景。这种”上下文复利”效应,让AI助手真正具备了”记忆”和”理解”。
十、核心竞争力的迁徙:PM的”不变”与”变”
AI不会淘汰产品经理,但会淘汰那些只会画图和传话的产品经理。
不变的是核心能力: 判断力、批判性思维、用户洞察、商业决策。这些思考性的工作才是产品经理真正的价值所在。AI最擅长的模仿和执行,如果你也只会模仿和执行,无论你在哪个岗位,都会最先被替代。
变的是能力配比和时间分配:
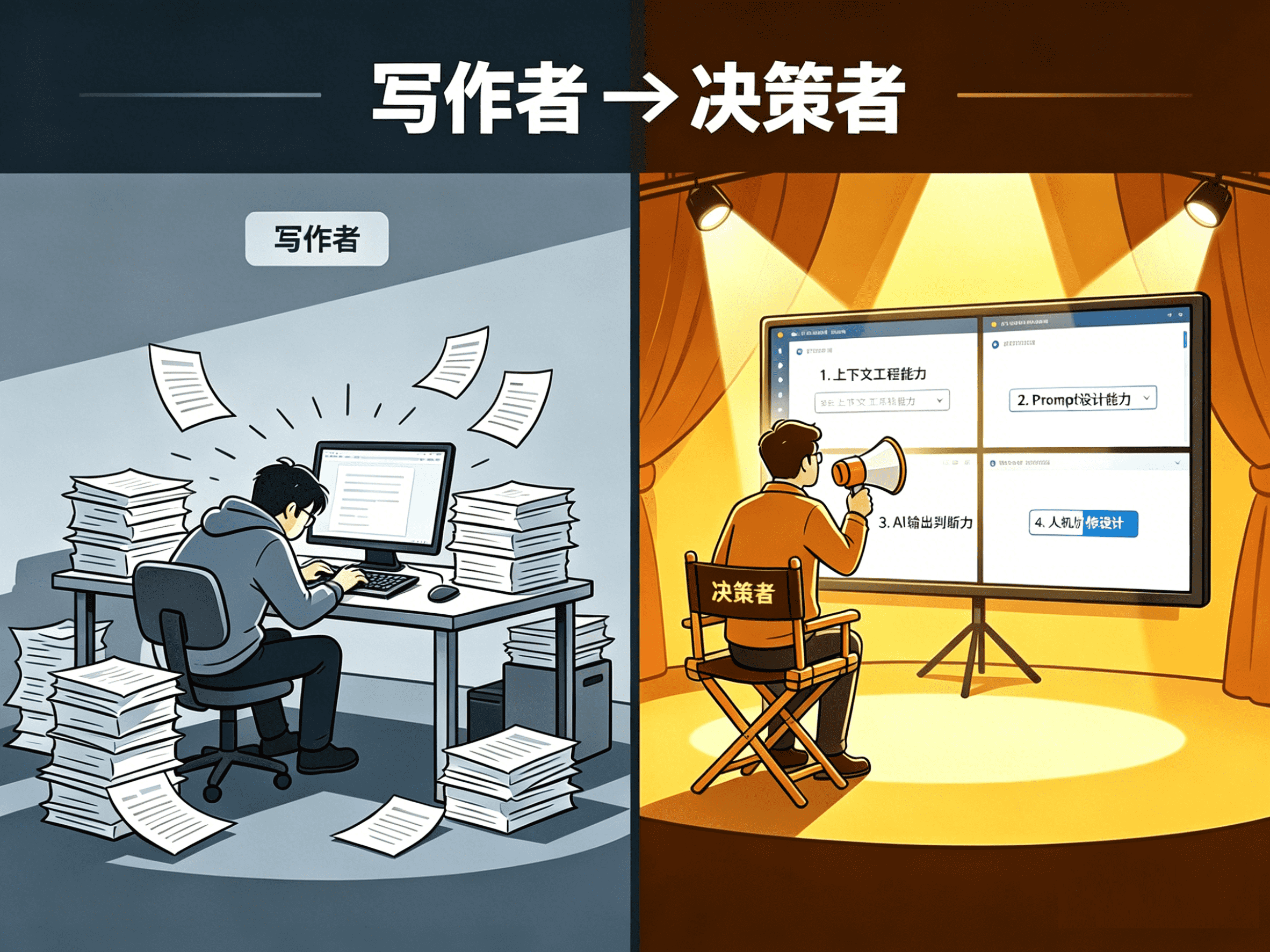
- 从”写作者”变成”决策者”:选合适的AI工具,用精准的Prompt传达需求,review AI输出判断对错,最终决策永远在人
- 从”文档时间60%”变成”思考时间80%”:省下的不是思考时间,是文档时间
- 从”单点工具使用者”变成”工作流编排者”:设计AI Agent的协作方式,比使用单个工具更重要
新的核心竞争力包括:
- 上下文工程能力:如何给AI提供完整、精确、无歧义的上下文,减少幻觉
- Prompt设计能力:将产品思维转化为AI可执行的指令结构
- AI输出判断力:在AI生成的大量内容中,快速识别对错、优劣
- 人机协作设计:设计人类与AI的协作界面,让AI在正确的时间做正确的事

写在最后:潮水的方向
AI时代产品经理的工作流重构,本质上是从”文档驱动”到”智能驱动” 的范式迁移。传统流程是线性的、串行的、人依赖的;新流程是网状的、并行的、人机协作的。
这种重构不是让PM变得更轻松——事实上,对判断力和学习能力的要求更高了——而是让PM回归本质。从被文档和会议淹没的”工具人”,变成专注洞察和决策的”思考者”。
如果你已经掌握了Vibe Coding设计原型,不妨做一个实验:把你手头的Demo代码发给AI,让它反向生成一份PRD。你会惊讶地发现,AI甚至比你考虑到了更多的Edge Cases。这,就是进化的开始,也让”一人成军”成为可能。
潮水流动的方向已经明确。有人在水里游泳,有人在岸上观望。你选择做哪一个?
- 标题: AI是如何重塑产品经理工作流的?
- 作者: xuliyaoPro
- 创建于 : 2026-05-05 00:00:00
- 更新于 : 2026-05-05 00:00:00
- 链接: https://chinapmcc.com/2026/05/05/1.定义与规划/1.1基础认知与职业启航/AI是如何重塑产品经理工作流的?/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


